Į±╠ņŻ¼└źü÷╚fŠSš²╩Į═Ų│÷Š▀ėąÅ═ļs╦╝┐╝═Ų└Ē─▄┴”Ą─ŽĄ┴ą─Żą═——ĪĖ╠ņ╣ż┤¾─Żą═4.0Ī╣ o1░µŻ©Skywork o1Ż®ĪŻ 
Skywork o1╩Ūė╔└źü÷╚fŠS╝»łF░l▓╝Ą─Š▀ėą┬²╦╝┐╝═Ų└Ē─▄┴”Ą─ŽĄ┴ą─Żą═ĪŻ▀@╩Ūć°ā╚Ą┌ę╗┐Ņųą╬─▀ē▌ŗ═Ų└Ē─▄┴”Ą─o1─Żą═ĪŻ▓╗═¼ė┌¼FėąĄ─Å═¼FOpenAI o1─Żą═Ą─╣żū„Ż¼Skywork o1▓╗āHį┌─Żą═▌ö│÷╔Žā╚╔·┴╦╦╝┐╝ĪóėŗäØĪóĘ┤╦╝Ą╚─▄┴”Ż¼═¼ĢrŻ¼įōķ_į┤─Żą═į┌ś╦£╩įu£y╝»╔ŽŻ¼ī”▒╚Ųš═©─Żą══Ų└Ē─▄┴”┤¾Ę∙╔Ž╔²Ż¼šµš²ūī─Żą═ōĒėą┴╦╦╝┐╝║═Ę┤╦╝ĦüĒĄ─═Ų└Ē─▄┴”Ą─╠ß╔²ĪŻłFĻĀÅ═¼Fo1Ą─╝╝ąg┬ĘŠĆŻ¼╩╣Ą├│§╩╝═Ų└Ē─▄┴”▌^▓ŅĄ─╗∙ū∙─Żą═į┌╗∙£╩£yįć╝»╔Ž│╔×ķ╔·æB╬╗SOTAĪŻ ┤╦┤╬░l▓╝Ą─Skywork o1░³└©╚²┐Ņ─Żą═Ż¼╝╚ėą╗žüķ_į┤╔ńģ^Ą─ķ_Ę┼░µ▒ŠŻ¼ę▓ėą─▄┴”Ė³ÅŖĄ─īŻė├░µ▒ŠŻ║ 1Ż¼Skywork o1 OpenŻ║ę╗┐Ņ╗∙ė┌Llama 3.1 8BĄ─ķ_į┤─Żą═Ż¼įō─Żą═į┌═¼╔·æB╬╗ķ_į┤─Żą═ųąįu£yųĖś╦┤¾Ę∙╠ß╔²▀_ĄĮSOTA╦«ŲĮŻ¼▓óĮŌµi┴╦įSČÓ▌p┴┐╝ē─Żą═¤oĘ©ĮŌøQĄ─Å═ļsöĄīW╚╬äšĪŻįō─Żą═Ą─░l▓╝ę▓īóÄ═ų·╝ė╦┘ć°ā╚ķ_į┤╔ńģ^Å═¼Fo1Ą─▀M│╠ĪŻ 2Ż¼Skywork o1 LiteŻ║įō─Żą═Š▀éõ═Ļš¹Ą─╦╝┐╝─▄┴”Ż¼Š▀ėąĖ³║├Ą─ųą╬─ų¦│ų║═Ė³┐ņĄ─═Ų└Ē║═╦╝┐╝╦┘Č╚ĪŻį┌öĄīWĪóųą╬─▀ē▌ŗ║══Ų└ĒŅÉå¢Ņ}╔Ž▒Ē¼F═╗│÷ĪŻ 3Ż¼Skywork o1 PreviewŻ║▀@┐Ņ─Żą═╩Ū▒Š┤╬═Ļš¹░µĄ─═Ų└Ē─Żą═Ż¼┤Ņ┼õūį蹥─ŠĆ╔Ž═Ų└Ē╦ŃĘ©Ż¼ī”▒╚Skywork o1 Liteėąų°Ė³ČÓśė║═“╔ŅČ╚”Ą─╦╝┐╝▀^│╠Ż¼Ė³═Ļ╔Ų║═Ė³Ė▀┘|┴┐Ą─═Ų└ĒĪŻ ŲõųąŻ¼╬ęéāķ_į┤Ą─Skywork o1 OpenŻ¼į┌Ė„ĒŚöĄīW║═┤·┤aųĖś╦╔ŽŠ∙ėą┤¾Ę∙╠ßĖ▀Ż¼īóLlama-3.1-8BĄ─ąį─▄└ŁĄĮ═¼╔·æB╬╗SOTAŻ©│¼įĮQwen-2.5-7B instructŻ®ĪŻ═¼ĢrŻ¼8BĄ─Skywork o1 Openę▓ĮŌµi┴╦║▄ČÓ▌^┤¾┴┐╝ē─Żą═Ż¼╚ńGPT 4oŻ¼¤oĘ©═Ļ│╔Ą─öĄīW═Ų└Ē╚╬䚯©╚ń24³cėŗ╦ŃŻ®ĪŻ▀@ę▓×ķ═Ų└Ē─Żą═į┌▌p┴┐╝ēįOéõ╔Ž▓┐╩╠ß╣®┴╦┐╔─▄ąįĪŻ 

═¼ĢrŻ¼╬ęéāę▓īóķ_į┤ā╔éĆ═Ų└Ē╚╬䚥─Process Reward ModelŻ©PRMŻ®Ż║Skywork o1 Open-PRM-1.5B ║═Skywork o1 Open-PRM-7BŻ¼ŽÓ▒╚┤╦Ū░ķ_į┤Ą─Skywork-Reward-ModelāHī”š¹éĆ─Żą═╗ž┤▀Mąą┤“ĘųŻ¼Skywork o1 Open-PRM─▄Įo─Żą═╗ž┤ųąĄ─├┐éĆ▓Į¾E▀Mąą┤“ĘųĪŻ ī”▒╚ķ_į┤╔ńģ^¼FėąĄ─PRMŻ¼Skywork o1 Open-PRM-1.5B─▄▀_ĄĮķ_į┤╔ńģ^8BĄ──Żą═ą¦╣¹Ż¼└²╚ńRLHFlowĄ─Llama3.1-8B-PRM-Deepseek-DataŻ¼OpenRĄ─Math-psa-7BŻ¼Skywork o1 Open-PRM-7B─▄═¼Ģrį┌┤¾▓┐Ęųbenchamrk╔ŽĮėĮ³/│¼▀^10▒Č┴┐╝ēĄ─Qwen2.5-Math-RM-72BĪŻSkywork o1 Open-PRMę▓╩ŪĄ┌ę╗┐Ņ▀m┼õ┤·┤aŅÉ╚╬䚥─ķ_į┤PRMĪŻŽ┬├µ▒ĒĖ±×ķęįSkywork-o1-Open-8Bū„×ķ╗∙ĄA─Żą═Ż¼╩╣ė├▓╗═¼PRMį┌öĄīW║═┤·┤aįu£y╝»╔ŽĄ─įu╣└ĮY╣¹ĪŻ 

│²Skywork-o1-Open-PRM═ŌŻ¼Ųõ╦¹ķ_į┤PRMŠ∙╬┤ßśī”┤·┤aŅÉ╚╬äš▀MąąīŻķTā×╗»Ż¼╣╩▓╗▀Mąą┤·┤a╚╬䚥─ŽÓĻPī”▒╚ĪŻ įö╝Ü╝╝ągł¾Ėµę▓īóį┌▓╗Š├║¾░l▓╝ĪŻ─┐Ū░─Żą═║═ŽÓĻPĮķĮBį┌Huggingfaceķ_į┤Ż©ķ_į┤ĄžųĘŻ║https://tinyurl.com/skywork-o1Ż® ÅŖ═Ų└Ēęį╝░ūį╬ęĘ┤╦╝Ą──▄┴”╩Ū╚ń║╬ŠÜ│╔Ą─Ż┐ Skywork o1į┌▀ē▌ŗ═Ų└Ē╚╬äš╔Žąį─▄Ą─┤¾Ę∙╠ß╔²Ą├ęµė┌╠ņ╣ż╚²ļAČ╬ūį蹥─ė¢ŠÜĘĮ░ĖŻ║ 1Ż¼═Ų└ĒĘ┤╦╝─▄┴”ė¢ŠÜŻ║═©▀^ūį蹥─ČÓųŪ─▄¾w¾wŽĄśŗįņĖ▀┘|┴┐Ą─Ęų▓Į╦╝┐╝Ż¼Ę┤╦╝║═“×ūCöĄō■ĪŻ═©▀^Ė▀┘|┴┐Ą─ĪóČÓśėąįĄ─ķL╦╝┐╝öĄō■ī”╗∙ū∙─Żą═▀Mąą└^└mŅAė¢ŠÜ║═▒OČĮ╬óš{ĪŻ, 2Ż¼═Ų└Ē─▄┴”ÅŖ╗»īW┴ĢŻ║łFĻĀčą░l┴╦ūŅą┬Ą─▀m┼õĘų▓Į═Ų└ĒÅŖ╗»Ą─Skywork o1 Process Reward ModelŻ©PRMŻ®ĪŻīŹ“×ūC├„Skywork-PRM┐╔ėąą¦Ą─▓ČūĮĄĮÅ═ļs═Ų└Ē╚╬äšųąķg▓Į¾E║═╦╝┐╝▓Į¾Eī”ūŅĮK┤░ĖĄ─ė░ĒæĪŻĮY║ŽūįčąĘų▓Į═Ų└ĒÅŖ╗»╦ŃĘ©▀Mę╗▓Į╝ėÅŖ─Żą══Ų└Ē║═╦╝┐╝─▄┴”ĪŻ 3Ż¼═Ų└ĒplanningŻ║╗∙ė┌╠ņ╣żūį蹥─Q*ŠĆ╔Ž═Ų└Ē╦ŃĘ©┼õ║Ž─Żą═į┌ŠĆ╦╝┐╝Ż¼▓óīżšęūŅ╝č═Ų└Ē┬ĘÅĮĪŻ▀@ę▓╩Ū╚½Ū“╩ū┤╬īóQ*╦ŃĘ©īŹ¼F║═╣½ķ_ĪŻQ*╦ŃĘ©┬õĄžę▓┤¾┤¾╠ß╔²┴╦─Żą═ŠĆ╔Ž═Ų└Ē─▄┴”ĪŻ
┴┴³c╣”─▄┼cīŹ£y Skywork o1─Żą═Š▀ėąęįŽ┬─▄┴”║═┴┴³c╣”─▄Ż║ 1Ż¼─Żą═╦╝┐╝║═ęÄäØ─▄┴” 2Ż¼─Żą═ūį╬ęĘ┤╦╝─▄┴” 3Ż¼─Żą═ūį╬ę“×ūC─▄┴” ŽÓ▌^ė┌┤╦Ū░Ż©ķL╬─▒Š╚╬䚯®┤¾─Żą═Ż¼¤ošō╩Ū│ŻūR═Ų└Ēå¢Ņ}Īó▀ē▌ŗ═Ų└Ēå¢Ņ}ĪóöĄīW═Ų└Ēå¢Ņ}ĪóéÉ└ĒøQ▓▀å¢Ņ}Īó▀Ć╩Ū“╚§ųŪ”Ż©ŅÉ╦Ų─XĮŅ╝▒▐DÅØŻ®▀ē▌ŗŽ▌┌Õå¢Ņ}Ą╚Ż¼Skywork o1Č╝╠Ä└ĒĄ─ė╬╚ąėąėÓĪŻš¹¾wüĒšfŻ¼Skywork o1 Lite║═Skywork o1 PreviewŠĆ╔Ž░µ▒Šį┌Å═ļså¢Ņ}Ęų╬÷Īó╦╝┐╝Ę┤╦╝▀^│╠Īó▌ö│÷┤░Ė┘|┴┐╔ŽŠ∙ėą┤¾Ę∙╠ß╔²ĪŻ ╩ūŽ╚Ż¼╬ęéā─├ę╗Ą└ĪĖ2024─Ļ╚½ć°┤T╩┐蹊┐╔·╚ļīWĮyę╗┐╝įćöĄīW(ę╗)įćŅ}Ī╣┐╝┐╝╦³Ż©╚ńŽ┬łD╦∙╩ŠŻ®Ż¼£yįćę╗Ž┬╦³Ą─“ųŪ┴”╦«ŲĮ”ĪŻ 
├µī”ļyČ╚▓╗ąĪĄ─ūŅą┬┐╝čąöĄīWŅ}Ż¼Skywork o1 Preview▒M╣▄╗©┘M┴╦ę╗ą®ĢrķgŻ¼Ą½▀Ć╩Ūę╗▓Į▓Į═Ų└Ē│÷┴╦š²┤_ĮY╣¹ĪŻ ─Ū├┤Ż¼ų«Ū░┤¾─Żą═Įø│ŻĘŁ▄ćĄ─▒╚┤¾ąĪå¢Ņ}Ż¼Skywork o1¼Fį┌Ą─╗ž┤╦«ŲĮ╚ń║╬┴╦Ż┐ 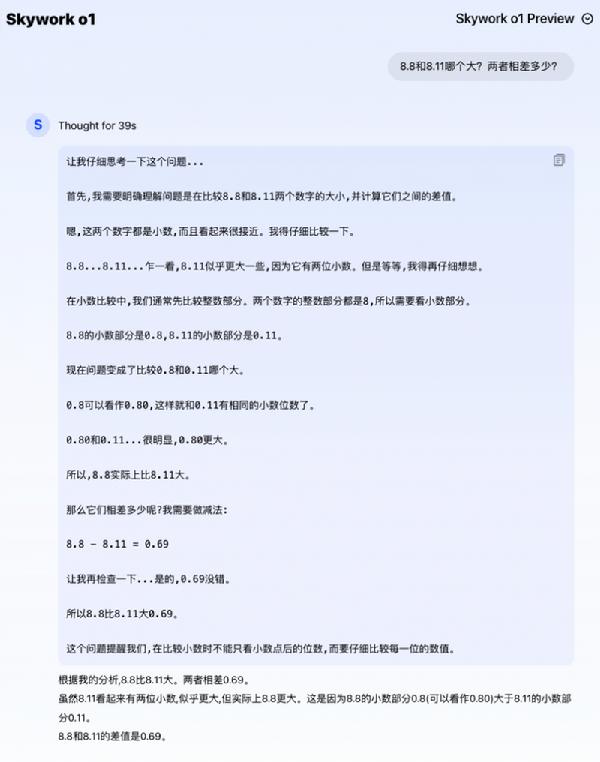
Å─╦³Ą─╦╝┐╝▀^│╠┐╔ęį┐┤│÷Ż¼Skywork o1Ą──Żą═╦╝┐╝║═ęÄäØ─▄┴”┤¾Ę∙╠ß╔²ĪŻ▀@éĆĮŌŅ}▀ē▌ŗĘŪ│ŻŽ±╚╦ŅÉĄ─╦╝┐╝ĘĮĘ©┴╦Ż¼“╚ń╣¹š¹öĄ▓┐ĘųŽÓ═¼Ż¼─Ū├┤Š═ę¬ķ_╩╝▒╚▌^ąĪöĄ▓┐Ęų┴╦”ĪŻ═©▀^ć└ųöĄ─═Ų└Ē▀^│╠Ż¼£╩┤_Ą├│÷8.8┤¾ė┌8.11Ż¼ŪęČÓĮo│÷┴╦ę╗▓Į▓ŅųĄėŗ╦ŃĪŻ ┤╦═ŌŻ¼─Żą═ūį╬ęĘ┤╦╝─▄┴”║═ūį╬ę“×ūC─▄┴”ę▓Č╝ėąķLūŃ▀M▓ĮĪŻSkywork o1┐╔ęį£╩┤_ūRäe│÷“n©½ h©Żo h©¦n g©Īo xìng rèn shí n©½”Ż¼▀Ć┐╔ęįĮo│÷║¾└mī”įÆĮ©ūhĪŻ 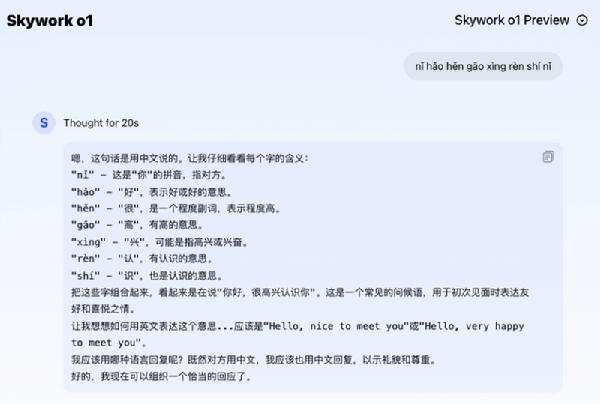

▒M╣▄╬ęéāūī╦³╗ž┤┤µį┌ųą╬─ūx궓Ž▌┌Õ”Ą─å¢Ņ}——“šłīóqíng rén y©Żn l©½ ch©▒ x©® sh©®▐DōQ×ķųą╬─”Ż¼╦³ę▓ø]ėą▒╗╬ęéā└@▀M╚źĪŻ│õĘųš╣╩Š┴╦ųą╬─▀ē▌ŗå¢Ņ}╦╝┐╝ųąĄ─Ę┤╦╝─▄┴”Ż¼╦³ų„äė░l¼F┴╦“╬„įŖ”╩Ū▓╗ī”Ą─šfĘ©Ż¼Č°╩Ū“╬„╩®”ĪŻ ═¼śėĄ─Ż¼ī”ė┌ų«Ū░Ą─┤¾─Żą═üĒšfŻ¼“╦Ń24³c”Ą─ė╬æ“║▄╚▌ęū░č─Żą═ĖŃ▒└Øó┴╦Ż¼Ą½╩Ūī”ė┌Skywork o1üĒšfŻ¼┐╔ų^╩ŪąĪ▓╦ę╗Ą·ĪŻ╦³▓╗āHĮo│÷┴╦š²┤_┤░ĖŻ¼ųž³c╩Ū╦³į┌▀^│╠ųą▀Mąą┴╦ĪĖūį╬ę“×ūCĪ╣ĪŻ╦³į┌ėŗ╦Ń▀^║¾Ż¼ėųÖz▓ķ┴╦ę╗▒ķŻ¼┤_šJ▀^│╠║═┤░Ė╚½▓┐Ę¹║Ž├³Ņ}ę¬Ū¾Ż¼▓┼Įo│÷ūŅĮK┤░ĖĪŻ 
│²┴╦╔Ž╩÷Įo│÷Ą─öĄīW═Ų└ĒĪó▒╚┤¾ąĪĪóųą╬─▀ē▌ŗęį╝░24³cėŗ╦ŃĄ─╚╬äš═ŌŻ¼Skywork o1į┌Ųõ╦¹Å═ļsĄ─ł÷Š░ę▓ėą▌^║├▒Ē¼FŻ║ Ėé┘ÉöĄīWŻ║Skywork o1─├ĄĮ2024 AIMEĄ┌ę╗Ņ}Ż©╚ńŽ┬łD╦∙╩ŠŻ®Ż¼ę▓Å─╚▌æ¬ī”ĪŻėŗ╦Ń▀ē▌ŗŪÕ╬·Īó╣½╩Įš╣╩Š┴„Ģ│Ż¼ėŗ╦ŃĢrķLę▓├„’@Š▀ėąā×ä▌ĪŻ 

├▄┤aĮŌ├▄Ż║į┌Å═ļs├▄┤aĮŌ├▄╚╬äšųąŻ¼Skywork o1ōĒėąÅŖ┤¾Ą─ūį╬ę╠Į╦„║══Ų└Ē─▄┴”ĪŻ 
į┌ęčų¬ĪĖįŁ╬─→├▄╬─Ī╣Ą─Ū░╠ߎ┬Ż¼Įø▀^ę╗ŽĄ┴ąÅ═ļs═Ų└Ē║¾│╔╣”Įo│÷┤░ĖŻ©╚ńŽ┬łD╦∙╩ŠŻ®ĪŻ 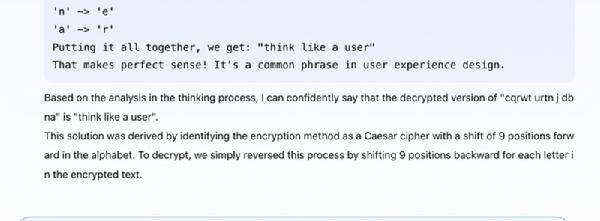
╚ń╣¹Ę┤▀^üĒ─žŻ┐ęčų¬ę╗Č╬ĪĖ├▄╬─→įŁ╬─Ī╣Ż¼─▄ʱšę│÷ą┬├▄╬─╦∙ī”æ¬Ą─įŁ╬─ĪŻSkywork o1▒Ē╩ŠąĪ▓╦ę╗Ą·ĪŻ 
ųŪ┴”å¢┤Ż║į┌Å═ļsĄ─ųą╬─═Ų└Ēå¢Ņ}╔ŽŻ¼Skywork o1▒Ē¼Fā׫ɯ¼▓óĮo│÷┴╦═Ļš¹Ą─╦╝┐╝µ£┬ĘĪŻ 

ūŅ║¾Ż¼į┘ūī╬ęéāį┘Įo╦¹│÷ę╗ą®ėą╚żĄ─“╚§ųŪ”å¢Ņ}Ż¼üĒ┐┤┐┤╦³Ą─╗ž┤╩Ū▓╗╩Ū║Ž└ĒĪŻ 1Ż¼×ķ╩▓├┤╬ę░ųŗīĮY╗ķĄ─Ģr║“ø]č¹šł╬ęģó╝ė╗ķČY? 2Ż¼▒╗ķTŖA▀^Ą─║╦╠ęŻ¼▀Ć─▄ča─Xå߯┐ 3Ż¼╬ń▓═╚ŌŻ¼╬ę┐╔ęį═Ē╔Ž│įåß? 

┴Ņ╚╦¾@Ž▓Ą─╩ŪŻ¼Skywork o1▓╗Ą½ø]ėą▒╗å¢Ņ}└@▀M╚źŻ¼▀ĆĘų╬÷Ą─Ņ^Ņ^╩ŪĄ└Ż¼╔§ų┴═Ė┬Č│÷“┤¾ųŪ╗█”Ż¼ę²╔Ļ│÷┴╦ę╗ą®Ė³ĄūīėĄ─╦╝┐╝ĪŻ ▀MļA░µĄ─Å═ļs╚╦ŅÉ╦╝┐╝─▄┴”Ą─ĮŌµię▓īó▀Mę╗▓Įį┌┤╣ŅÉŅIė“į÷ÅŖ┤¾─Żą═Ą─æ¬ė├Ż¼└²╚ńŻ║ 1Ż¼ųąėó╬─│ŻęŖ▀ē▌ŗ═Ų└Ē║═Å═ļs╚╬䚯¼╚ńöĄīW/┤·┤aŅÉ╚╬䚯¼┐ŲīW蹊┐ 2Ż¼Ė▀┘|┴┐ā╚╚▌╔·│╔Ż¼╚ńäōęŌīæū„Ż¼ąąśIł¾Ėµīæū„ 3Ż¼╔ŅČ╚╦č╦„Ż¼ĮŌµiÅ═ļs╦č╦„╚╬䚥─▓ĮŌ 2024─ĻęįüĒŻ¼└źü÷╚fŠS╠ņ╣żAI│ų└m▀M╗»Ż¼Ļæ└m░l▓╝┴╦ĪĖ╠ņ╣ż2.0Ī╣ĪóĪĖ╠ņ╣ż3.0Ī╣ĪóĪĖ╠ņ╣ż┤¾─Żą═4.0Ī╣4o░µ——Skywork 4oŻ¼ęį╝░Į±╠ņš²╩Į░l▓╝Ą─ĪĖ╠ņ╣ż┤¾─Żą═4.0Ī╣ o1░µŻ©Skywork o1Ż®Ż¼▓╗āH╩Ū╬ęéāž×Åž“All in AGI ┼c AIGC” æ┬įĄ─ųžę¬┼e┤ļŻ¼Ė³╩Ū╬ęéāśŗĮ©AI╝╝ągŚŻĄ─ųžę¬ę╗▓ĮĪŻ╬ęéāīó▒³│ų“īŹ¼F═©ė├╚╦╣żųŪ─▄Ż¼ūī├┐éĆ╚╦Ė³║├Ąž╦▄įņ║═▒Ē▀_ūį╬ꔥ─╩╣├³Ż¼Å──Żą═īėĪóæ¬ė├īėĄ╚╚½ĘĮ╬╗ĪóČÓŠSČ╚üĒśŗĮ©╣½╦Š╝╝ągĖéĀÄ┴”║═╔·æBŠžĻćĪŻ |


